Speech & Math
Mathematical and numerical modelling of speech
Currently, our compound model "Dico v.0.9" provides a reasonably complete acoustic description of vowel production. It is based on the acoustics of the vocal tract and subglottal cavities. The acoustic Webster's resonators (based on area functions and Webster's horn model) are coupled to an incompressible and non-turbulent scalar flow model that excites a low-order, non-symmetric mass-spring model of the vocal folds.
The model consists of two parts: the glottal pulse generator and the 3D acoustic simulator.
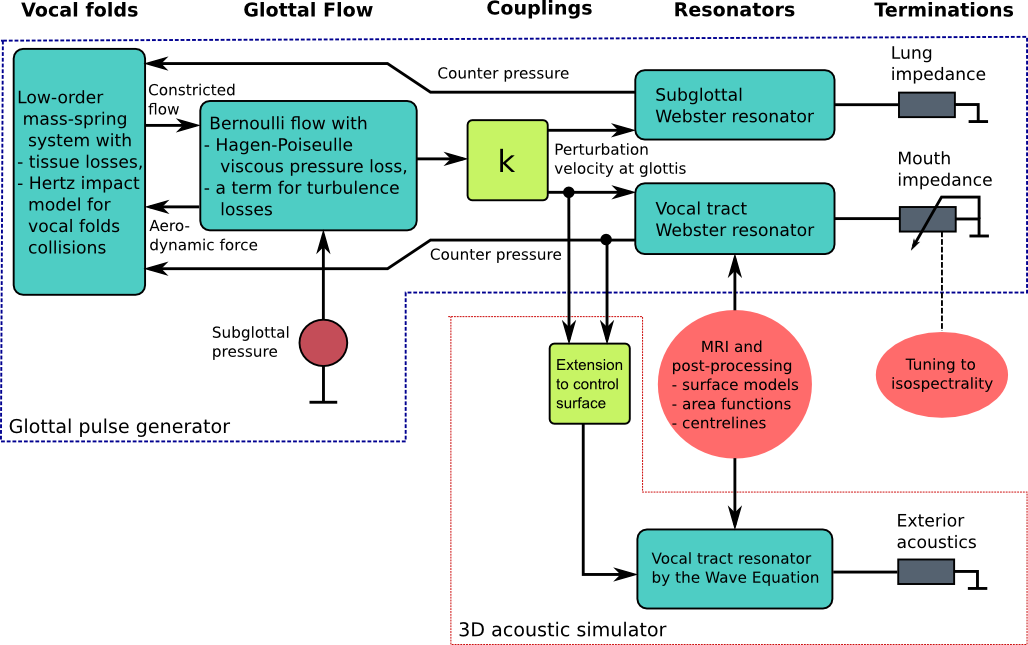
Feedback couplings from both Webster's resonators to the vocal folds masses have been realised, and separate models for acoustic, viscous, and turbulent energy losses as well as losses to tissues have been incorporated. They appear as terms in the respective (partial) differential equations.
The model has been so designed that vocal tract geometries from MRI can be easily introduced for simulations of the acoustic velocity potential. The sound pressure and perturbation velocity profiles can be obtained from the potential.
Because cross-mode resonances of the vocal tract must be captured, the final simulated signal is produced by a separate 3D acoustic simulator. It is a 3D wave equation solver that is boundary controlled by the same glottal signals that feed the vocal tract Webster's resonator. The area function for Webster's resonator corresponds to the vocal tract geometry of the wave equation resonator during simulations. Furthermore, the mouth termination of Webster's model is tuned to coincide the longitudinal resonance structure of the wave equation resonator, equipped with an exterior space model. This is ongoing work based on measurement data, and it requires a lot of preparations with MRI image post-processing as well as signal processing of measured speech.
The simulated glottis pulse, glottal opening area, and pressure signals corresponding to female phonation of [a] at f0 = 150Hz and subglottal driving pressure 1 kPa over the ambient. The black pulse form is obtained with decoupled subglottal resonator, and the red line when the first subglottal resonance is set at 500 Hz. The glottal opening and closing times are denoted by circles and squares, respectively.
The glottal pulse generator is not intended to be a physically realistic description of the glottal flow in the sense that flow separation, jet formation, and realistic vocal folds geometries are not included. Instead, it is designed to serve as a validated, tunable source of glottis pulse which adapts to changing vocal tract geometries and specifications of the phonation type. Part of the model parameters can be chosen based on physical material parameters but there are some parameters (in particular, in the glottal flow submodel) that must be tuned to obtain the desired glottal pulse form.
FEM is used for the spatial discretisation of vocal tract geometries in all parts of the model.
Data acquisition during MRI
High resolution modelling and model validation require large datasets from a large number of subjects in various phonetical configurations. To achieve high consistency of the data, speech samples and MRI must be collected simultaneously in the extremely difficult environment that the MRI room is. Special acoustic and electronic instrumentation has been developed in the project, aiming at the best possible final quality of speech signals as well as artefact-free MRI.


The speech and acoustic MRI noise samples are captured by a two-channel sound collector which sits tightly on the head and neck MRI coil. The samples are transmitted the first 3 m by acoustic waveguides.
The experimental system is highly automated, and it is able to trigger the MRI machine (Siemens Avanto 1.5T) in sync with the rest of the experimental arrangements. It requires two persons to run the experiments: one setting the operating parameters of the MRI machine and the other running the experiment control system software.


The microphone array is inside a sound-proof Faraday cage without ferromagnetic parts. From here, the signals are transmitted using shielded cables to the MRI control room where the rest of the analogue instrumentation as well as the computing equipment are located.
Using this measurement system, it is possible to record about 100 combined MRI- and speech samples during a session of about 1h. Most of the samples are steady vowels (using 3D MRI) but also some phonetically interesting sentences are being imaged (using dynamic sagittal plane scans).
Post-processing of the MRI and the sound data
Vectorisation of the MRI data
The MRI machine produces a stack of bitmaps stored in a DICOM file. The automatic extraction and artefact removal of the tissue-air interface from these images is a non-trivial task. Our custom software produces surface models that can be used for generating FEM meshes as well as vocal tract area functions. All this can be done with minimal manual effort, and thus large data sets can be processed.

The vocal tract anatomies of Finnish vowels, spoken by a 30-years-old healthy male subject in supine position. These geometries are from the data set that can be downloaded from the data section.
3D prints from the surface models
The vocal tract surface extraction code produces surface models as STL files. Such files can be 3D printed at low cost by, e.g., Fused Deposition Modelling (FDM) printers such as the Ultimaker. We have experimented with Ultimaker hardware to produce objects from the vocal tract in all vowel configurations. Even though the anatomic geometry is quite challenging to print using FDM technology, the approach seems promising from both price and quality points of views.
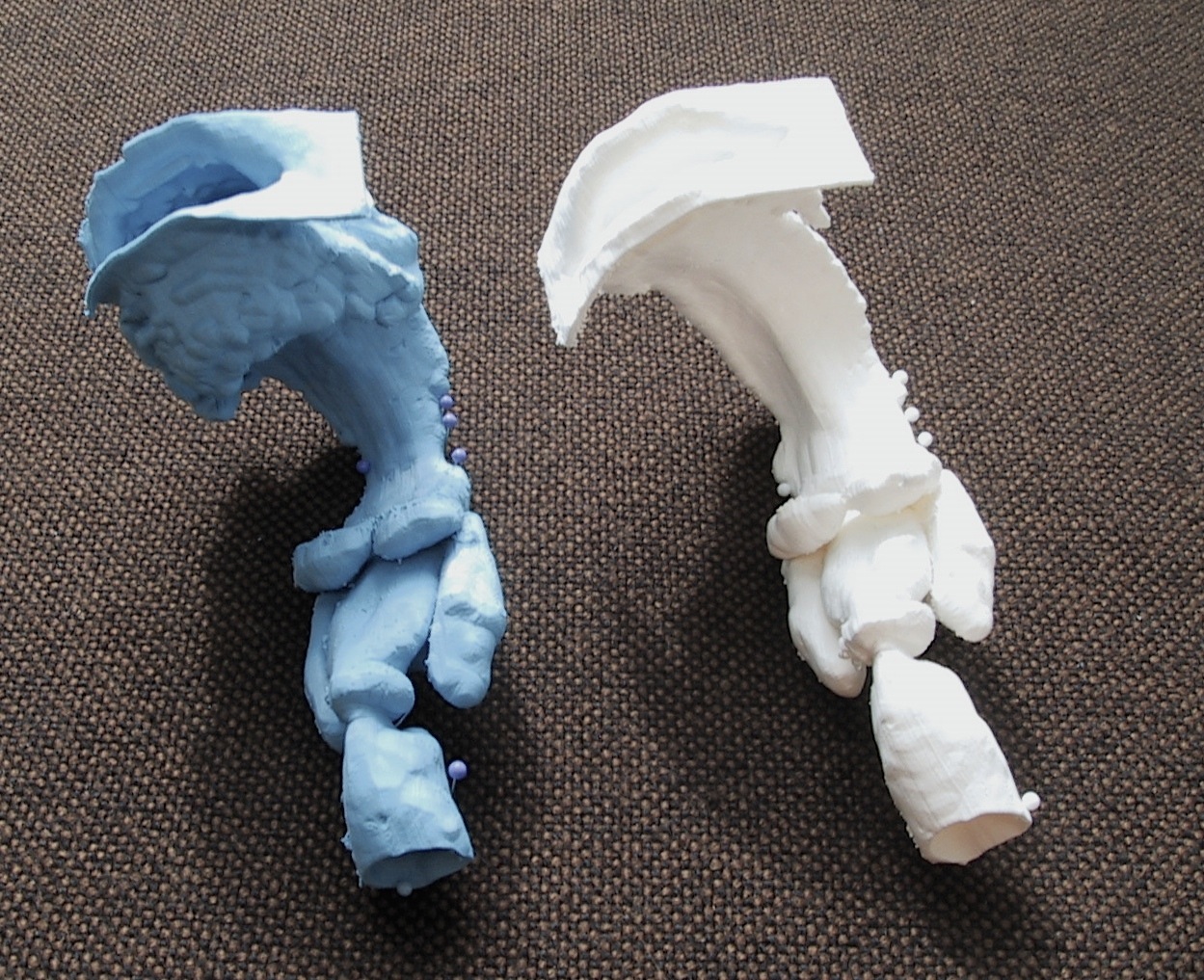
Vocal tract configurations of [a] and [e], printed in PLA with Ultimaker in scale 1:1. These geometries are from the data set that can be downloaded from the data section.
3D printed vocal tract models are expected to be useful in planning oral and maxillofacial surgery just as dental casts have been used in orthodontics for decades. And, of course, they will produce an audible vowel sound if you excite them acoustically at the glottis position.
Post-processing the speech data
The main purpose of the speech data post-processing is to get rid of the acoustic noise, generated by the MRI machine, that contaminates the samples. A significant noise reduction is achieved by the dipole configuration of the sound collector but digital signal processing is needed as well. Our solution is based on 1) the compensation of measured frequency responses of the system, and 2) adaptive spectral filtering using the acoustic noise profiles produced by the MRI sequences.

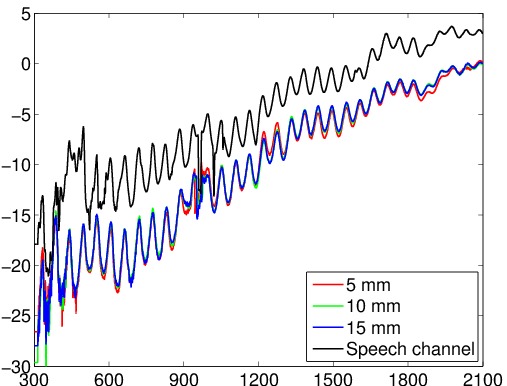
A lot of engineering and design was needed to improve the acoustic characteristics of the waveguides. Some of the remaining non-idealities are compensated by using a frequency response (right), measured in the anechoic chamber (left) of Dept. of Acoustics and Signal Processing, Aalto University (courtesy of prof. Paavo Alku).
We get almost clean steady vowel samples but the outcome of the dynamic speech samples is not quite as good.
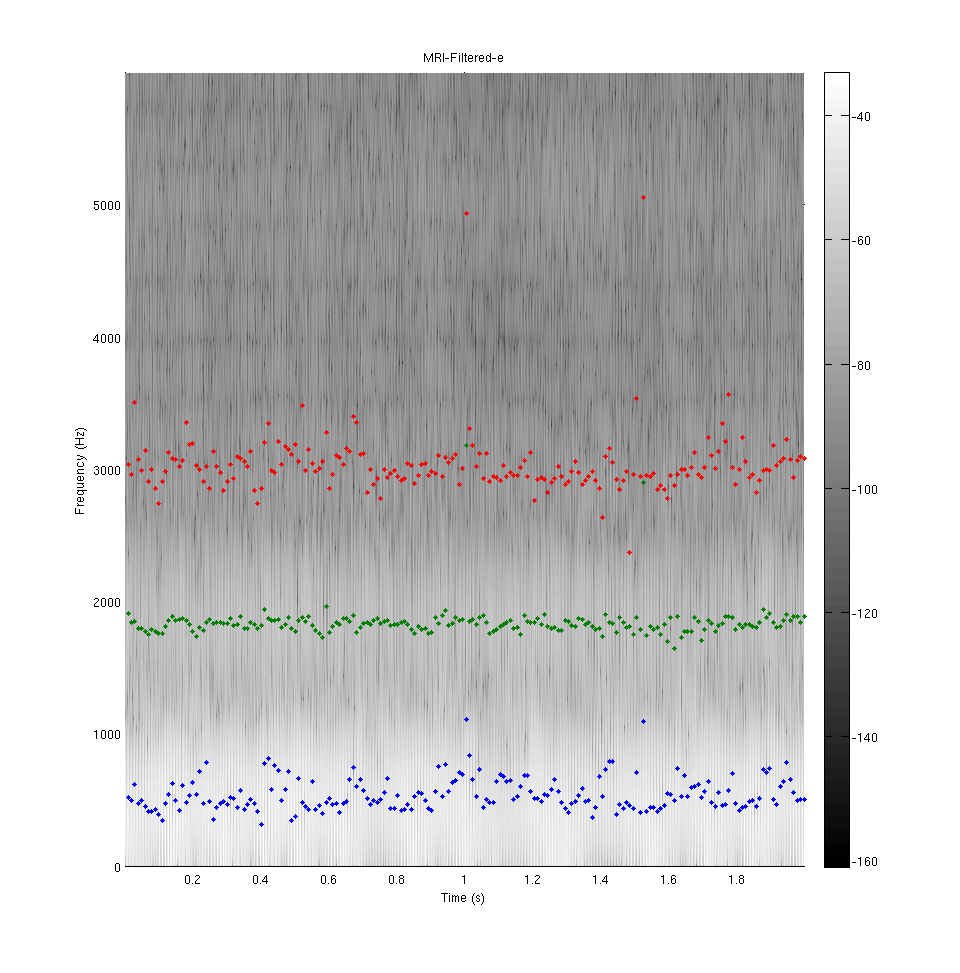
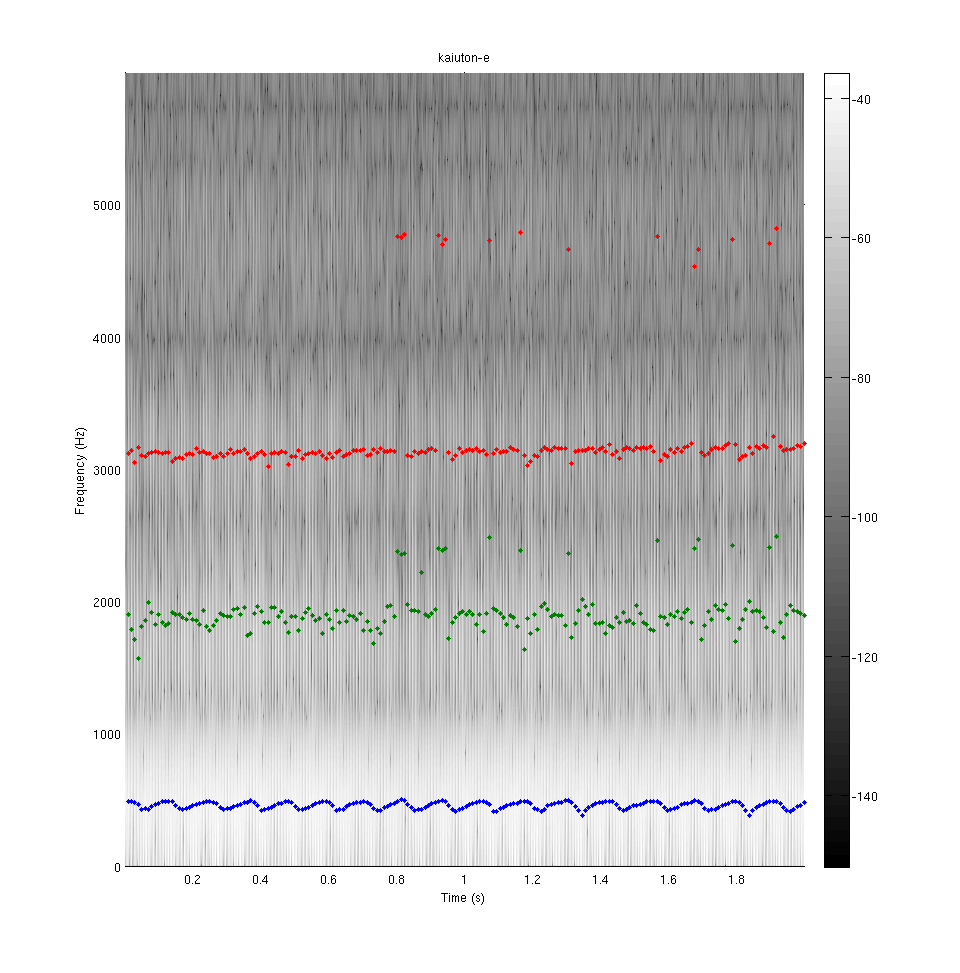
Three lowest formants (extracted by a custom LPC-based algorithm) of vowel [e] as pronounced by a 28-years-old healthy male subject in supine position. Signal recorded in MRI after clean-up on the left. A comparison sample recorded in the anechoic chamber on the right.
The data collection from patients in MRI
After many rounds of pilot MRI experiments for finishing up the experimental system, the first data from patients were obtained in autumn 2012. These subjects are patients of oral and maxillofacial surgery in Turku University Hospital. Each patient will be imaged twice: pre- and post-operatively.
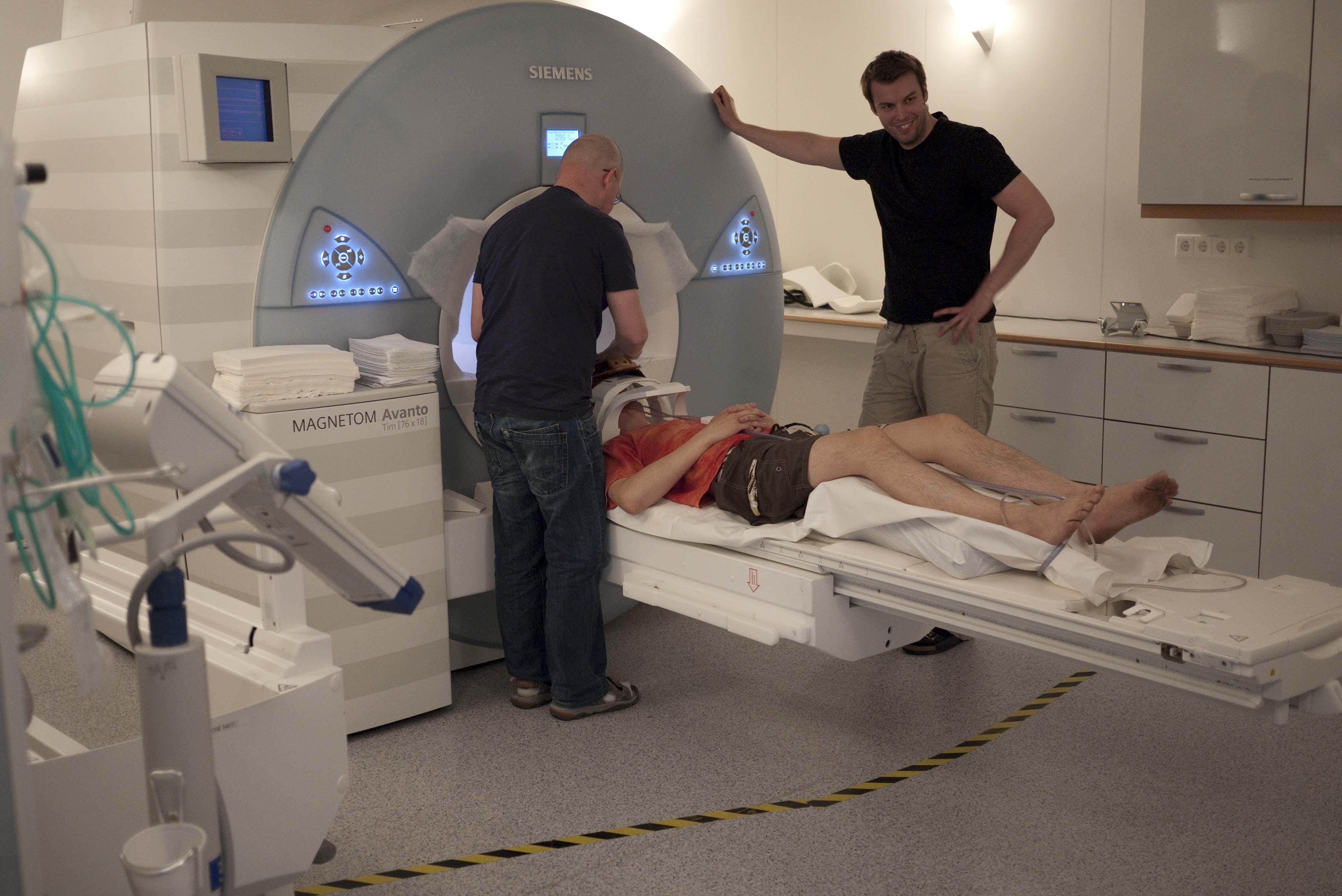
During the pilot phase, many of our group members underwent MRI examinations of the head and neck area. As side findings, the brain was positively detected in all researchers without exception.
The patient data can only be used within the strong restrictions imposed by the Research Ethics Board. We are, however, able to provide some separate datasets for educational use and academic research here.
Imaging of teeth
Teeth are not visible in MRI due to their low hydrogen content but they are an important acoustic element of the vocal tract. Hence, it is necessary to add separately imaged teeth geometry into the soft tissue geometry.
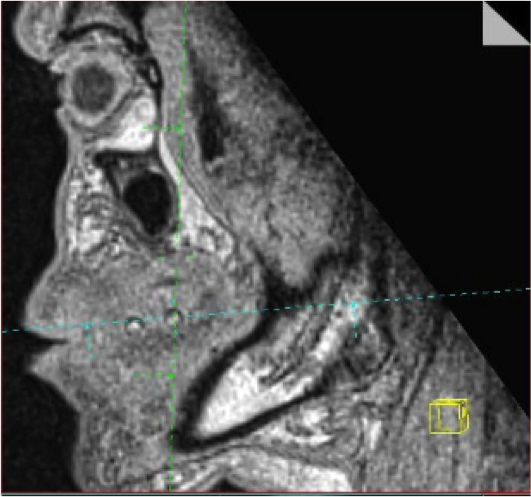

MRI visible markers provide coordinate points for teeth model alignment with respect to soft tissue geometries. The markers have been developed in the project (courtesy of Mr. Jarkko Malinen).
Optical scans of teeth or digitalised dental casts can be readily obtained from the patients but the alignment of the two geometries is a non-trivial problem. Markers containing vegetable oil, attached to the surface of the teeth, appear to be a practical approach that produces sufficient MRI visibility.